Meta的MusicGen有提供Github的open source,學術派的還可以去看它的paper,而在huggingface上就有可以直接操作,可以點下方有範例,簡單說就是可以輸入一段描述文字,另外可以額外輸入一段參考音樂來自檔案或麥克風,就能生成約15秒的音樂,產生的音樂可下載成MP3,操作畫面如下: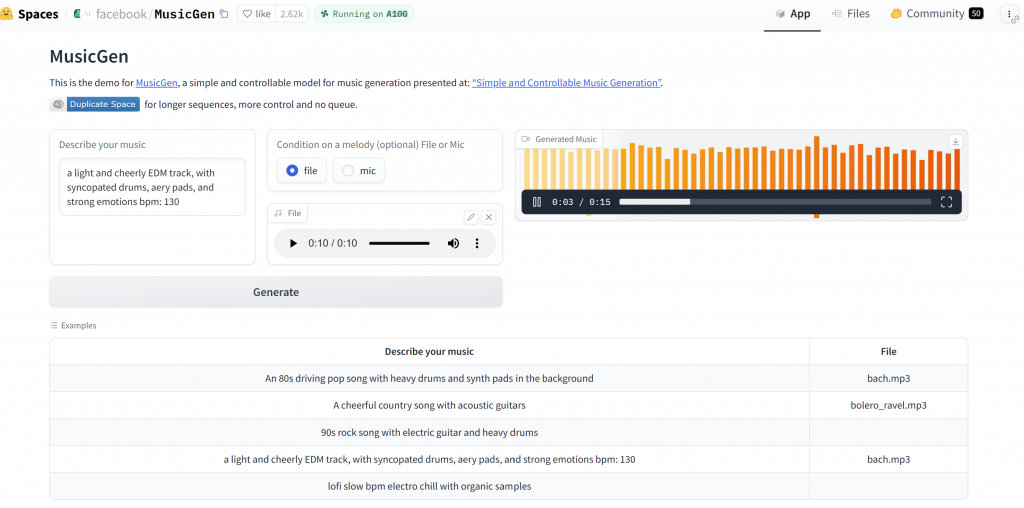
輸入文字我試過一些風花雪月的都能產生音樂,例如"we don't talk anymore",甚至中文"緩緩飄落的楓葉像思念",而生成的音樂跟原曲沒有關連性。比較可惜的就是只能生成15秒,而且音樂的組成和變化比較單純,即使提字是rock還是覺得是鄉村風。但這看它的文件有參數可以設定,進一步還是需要自己安裝來玩玩。
其他說明可以操考這篇蘋果仁。
OpenAI的MuseNet就比較像是概念的demo,在它的介紹網頁,可以選擇作曲風格,有蕭邦、莫札特、俄國作曲家拉赫曼尼諾夫、Lady Gaga,鄉村和迪士尼,然後有6個起始音樂可以選擇其一,點開下方的向右展開就會開始生成,會產生4個作品,同樣可以下載。音樂有點像以前一開始玩machine learning自己做簡單AI詩人那樣,根據起始音樂之後開始即興(放飛),根據我試到的結果,有三十幾秒到一分多鐘的長度。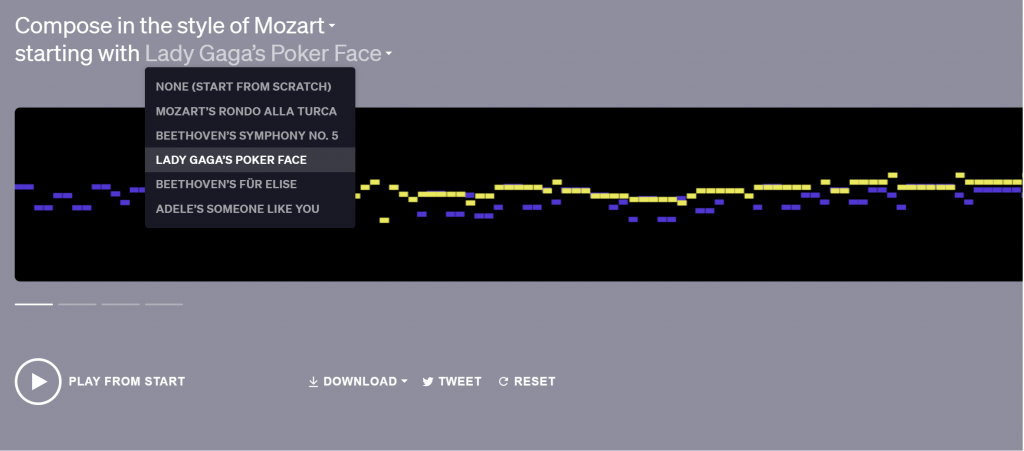
在這篇介紹文章中有更多選項和選擇可以設定,但我用的時候是沒有,就如我上面所列而已,


 iThome鐵人賽
iThome鐵人賽